The development of FinLiveRI data platform and service combining data from different research units has started in 2021 in collaboration with FinLive consortium and CSC. A data model for the first version has been defined and data base, data transfer and user interface are being developed. The aim is to have the first version of the data platform available for users via a web interface in 2022. Data model and all software implementation of the data service are open source.
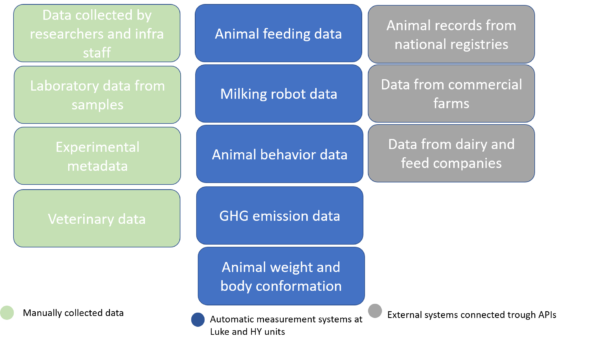
The aim of the common data service is to offer easy access to research facilities and research data on animal genetics, nutrition, health and welfare data. At present national livestock related data is fragmented in different places, and raw data, results and related publications are not linked, and are not findable by the scientific community. Also, the documentation about experiments will be stored enabling publishing in a structured format to ensure scientific reproducibility and data interoperability. The FinLive Data Service will offer data discovery and management, while reuse of research data is supported with documentation and harmonisation and functionalities that enable efficient reuse and data citation.
The Data Service will include a system where researcher can upload data and describe it using a standard format and controlled vocabulary and get a Persistent Identifier (PID) for their data. At this point the researcher could also define how openly available the data would be or for example whether it has an embargo period. When the description is published, it can be found by other users. Users can browse datasets available on the platform using a variety of search terms, including for example time periods or creator. The basic description of each dataset, license, format and linked articles would be open for everyone to view but depending on access rights the data itself might be restricted according to the policies. The user can request access to restricted data with a standardized process.